项目背景
随着时间的累积以及异地分行数据的接入,数据量逐渐增大,原计划是按照人民银行数据要求保存3个月,但后来更改为保存1年,目前每天约千万条数据,1年总计约数亿条数据,现有架构难以支撑。根据人民银行增加的蓝标需求,2017年开始冠字号系统又增加了新的查询场景,包括各种条件组合查询,比如按业务流水号进行冠字号码的查询。
目前银行冠字号数据存储在Hbase中,且通过Phoenix提供的JDBC接口,提供对外查询服务,目前项目查询过程中会存在响应时间长,甚至有交易失败的情况,影响业务办理。
项目需求
人民币冠字号码信息管理系统主要是为满足中国人民银行对现金冠字号码数据集中存储和查询的监管要求,为我行各分支机构涉假币纠纷时提供举证和责任认定手段,以减少伪钞纠纷,提高银行公信力。根据监管要求,现金冠字号码信息管理系统拟在该行所有现金机构进行部署。
考虑未来业务发展需要,行方业务部门预计日冠字号3000万条,查询反应时间10秒,系统保留100天的数据。
项目解决方案
系统架构
使用基于分布式数据库引擎技术的平台实现冠字号数据的集中存储和查询。

图1
数据处理流程图
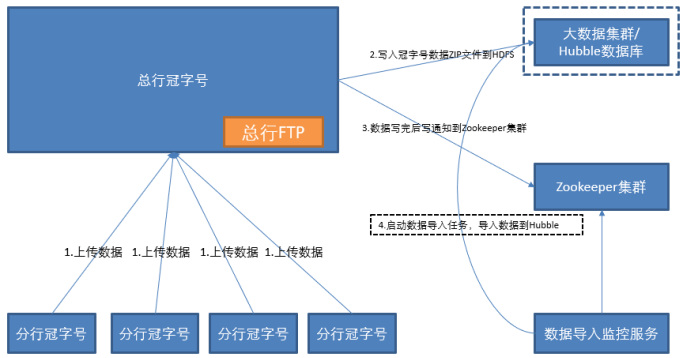
图2
数据流程描述
分行冠字号每天定期的将冠字号数据通过FTP协议上传到总行。总行冠字号系统每天定时将冠字号数据FSN ZIP文件调用HADOOP接口将数据上传到Hadoop指定目录下。
Hubble技术优势
1)依赖少运行稳定完善的快照机制;
2)分布式系统节点无限扩展 ;
3)与Hadoop生态体系完美融合;
4)数据存储3副本,确保数据不丢失 ;
5)数据亲密度计算,减少数据的移动;
6)数据传输优化提高集群间交互性能;
7)超强的性能,毫秒~秒级响应 ,支持批量加载,提升大数据量导入速度。
项目结果
- 实现现金冠字号码数据采集存储。系统可实现对机构使用的 A 类点钞机、具备现金清分功能的清分机进行标准化的现金冠字号信息数据采集,并对采集后的数据进行联网传输和集中存储。
- 对本行自助柜员机系统已采集的冠字号码数据进行归集,以满足监管实现冠字号码数据的集中存储要求。
- 实现现金冠字号码数据行辖内联网查询。业务人员可通过系统实现对已采集的冠字号码数据进行联网查询,可对数据进行精确查询和模糊查询,为机构与客户涉假币纠纷时提供举证和责任认定手段。
- 提高现金清分工作量统计水平。可根据查询权限分类别对辖属机构的现金清分情况进行统计,便于分行管理部门掌握各机构的现金运转情况,提高现金运行水平。