(1)多源异构是什么
简单来说就是多个数据源,不同的数据存储架构。
多个数据来源,这里的来源可能是 Mysql,Oracle这些数据库中文件;也可能是一些非结构化的 HDFS,ES这些非结构化数据库中的文件;还有一些就是通过 WEB 页面传递过来的 RESTful,Josn 字符串。
异构主要指数据结构上的差异性。数据结构层把纷繁复杂的数据归为三大类,针对每一类数据设计了相应的数据存储模型,确保了城市操作系统的扩展性和一致性。这三类数据包括:
结构化数据:以银行系统数据为代表,通常以人或者机构的ID为锚点来聚合不同的信息,如名称、职业、收入等;后续会演变出基础库、主题库、专题库等一系列组织形式。
非结构化数据:以视频、图像、语音和文本为代表,后续大多需要经过分析处理变成结构化数据才能被使用。
时空数据:以地理信息、物联网、轨迹数据为代表。
(2)为什么要多源异构
随着大数据与人工智能技术的应用普及,海量多源异构数据急剧增加,特别是非结构化数据的增加,当遇到复杂多场景混合事务分析型数据管理必然要涉及水平拆分,一旦进行拆分,就避免不了“原本在同一数据库里的查询,就变成跨多个数据库实例的查询”问题。随着技术的不断迭代,现在的数据库不仅仅只有关系型数据而且也有Nosql数据库等,这就对跨库关联提出了更大的挑战。
大数据的核心就是多源异构,每个源的数据都有自身的逻辑,有不同的形式进行描述。
而最终的目的是要把数据进行治理、融合、分析,这样就可以体现出整体数据中的现象和规律。
(3)Hubble硬核技术价值
Hubble数据库通过插件模式设计可以把Mysql、Oracle、Hbase、Hive等都可以作为Hubble的数据源,支持跨数据源查询。提供适配的多源异构数据资源接入方式,包括数据源的配置、数据任务的同步、数据的分发与调度、数据的ETL加工等;Hubble可以做到:
1)统一服务入口,接入各类数据库源系统;
2)自由编写SQL,实现数据访问服务;
3)无需将数据完全搬迁,即可以现有数据即席分析探查。
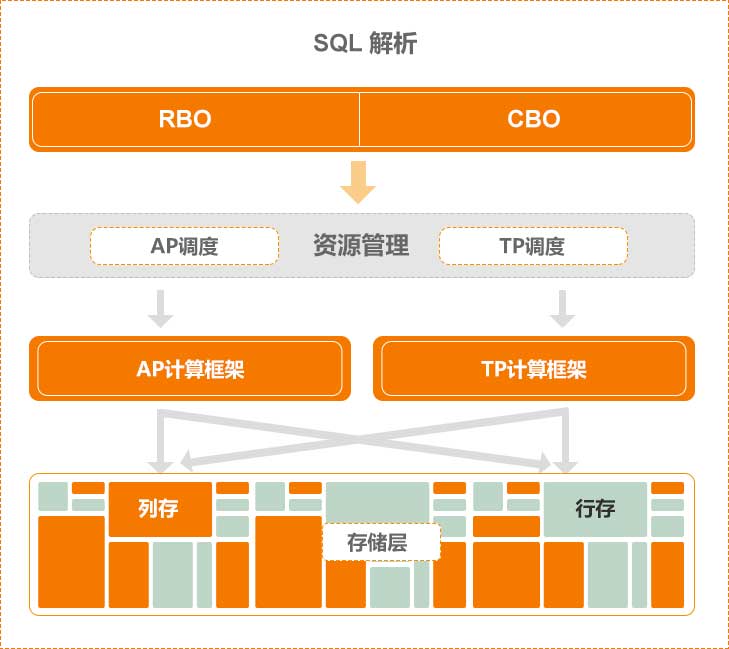
(1)什么是混合存储
混合存储又称行列混合存储,TP 和 AP 传统来说仰赖不同的存储格式:行存对应 OLTP,列存对应 OLAP,混合存储简单理解就是AP+TP混合存储。
(2)为什么需要混合存储
OLTP需要处理涉及频繁写操作的事务型查询,OLAP侧重于处理涉及大量读操作的分析型查询,列存储在读操作中有较大的优势,适合OLAP查询,但不适合OLTP查询。
随着大数据存储时代的到来,人们对于大容量、高性能和低成本的存储系统的需求更加迫切。混合存储充分利用不同类型存储器件的特性组成高效的存储系统,既能支持存储系统容量的大幅扩展,又能在保证系统低成本的前提下,显著提高存储系统的性能,成为当前存储系统领域的研究热点。
先来看一下单独行存储和列存储的优缺点
1)行存储时,数据按照元组直接进行存储,写的效率较高;列存储时,元组必须首先拆分成独立的属性列,再独立存储。
2)行存储时,在查询密集型应用中需读取整条记录,属性较多时读取数据代价较大;按列存储时,只需要读取所需要的属性列,大大减少读取数据的代价。
3)采用列存储时可以获得较高的压缩率,行存储不利于压缩。
在数据存储层上, Hubble采用基于切片的行式存储、列式存储和KV存储的混合部署模式。通过行式存储方式存储海量数据,支撑数据TP操作;列式存储和KV存储的混合部署模式,支撑数据AP操作。
(3)Hubble数据库硬核技术价值
在数据存储层上, Hubble采用基于切片的行式存储、列式存储和KV存储的混合部署模式。通过行式存储方式存储海量数据,支撑数据AP操作;列式存储和KV存储的混合部署模式,支撑数据TP操作;通过KV存储保持高效率的写入速度,支撑大数据体量。
1)KV存储把不常变动的一些数据存储在kvstore中,需要的时候直接凭借key拿出value就好,事务处理速度更快,适合事务处理,速度快实时性更有保障。
2)列存性能在OLAP分析时比行存储性能倍速提升;
3)支持随机的增、删、改、查操作,降低查询响应时间;
4)在数据中高效查找数据,无需维护索引(任何列都能作为索引),避免全表扫描。
5)在大规模数据同时支持密集AP计算和TP并发场景下, 基于数据切片的混布存储策略可以弹性适应IO特性,快速做库内转换,避免数据复制和冗余。
(1)什么是分布式SQL
分布式SQL可以称为分布式任务,分布式SQL是指SQL语句到任务执行的时候分布在多个机器上执行。
(2) 为什么要用分布式SQL
SQL是关系型数据库的通用语言,关系型数据库是单体式的,从架构而言它们无法在多个实例之间自动地分配数据和查询。
分布式SQL在查询上可以被自动地分配到目标群集的多个节点上,有效地避免了单个节点成为查询处理中的瓶颈问题。分布式SQL内置具有可扩容性、灵活性、以及地理分布特性。做TP(查询)计算时没有太大影响,在做AP(分析)计算时,性能会下降很多。
(3) Hubble硬核技术价值
分布式数据库,可以分为如下几类场景:第一种存储分布式、SQL单机化;第二种存储分布式、SQL分布式。
第一种只支持简单的增删改查,稍微复杂的分析SQL执行性能下降就会非常明显。第二种存储分布式、SQL分布式优点:1.可以把任务进行拆分充分利用计算资源,提升计算效率;2.对于有些大任务无法完成的,可以利用分布式任务来完成,提升了大任务的完成度。同时也存在了开发复杂度高、增加了调度的复杂度的问题。
a)Hubble数据库既可以支持存储分布式、SQL单机化也可以支持存储分布式、SQL分布式;
b)Hubble可以在不重启服务的情况下,通过修改配置,做到两种模式之间的切换;
c)Hubble数据库可以方便应对更多场景。
(1)什么是数据一致性
事务机制ACID和CAP理论是数据库和分布式系统中两个重要的概念,这两个概念中都有相同的“C”代表 "Consistency" 一致性。
ACID体现在数据库领域,其中ACID中的“C”数据一致性是指事务的执行不能破坏数据库数据的完整性和一致性,一个事务在执行之前和执行之后,数据库都必须处于一致性状态。 比如:A向B转账,A扣款的同时B到账。
CAP体现在分布式领域,其中CAP中的”C”数据一致性是指是所有副本在同一时间的数据完全一致,比如:A、B、C三个副本,A中写入数据”Hello”,写完马上读B和C,就一定要读出“Hello”读出来我们就称之为符合一致性。
(2)为什么需要数据一致性
为了更清楚的体现出数据一致性的重要程度,用举例的方式表达为什么需要数据一致性。举个简单的例子来描述一下这里数据一致性的含义。
程序员小张向女友小丽转账125元,转账过程是:先扣除小张125元,再为小丽的账户添加125元。如果在转帐过程中,扣款操作和打款操作要么同一时间执行,要么同一时间都不执行,我们就认为转帐过程保证了数据一致性。数据能否实现一致性,对金融、公安等重要行业来说至关重要。
(3) Hubble硬核技术价值
Hubble的数据一致性技术既包括ACID数据库中的数据一致性,又包括CAP分布式系统中的数据一致性,Hubble数据库可以做到最高级别可串行化。
a)用户体验感好;
b)支持串行化事务;
c)能保证多个事务并发时的执行顺序对数据的一致性没有影响。
(1)数据中心化的问题
a)数据中心化在查询涉及多关联场景时,会导致查询性能严重低下。
b)当大量数据存在于同一个数据库时会容易造成数据库访问瓶颈,从而影响数据访问性能,并为系统可用性埋下隐患。
(2)为什么需要去中心化
a)在云计算、大数据等新技术的带动下,越来越多的企业需要对结构化的数据进行查询、分析、处理和更新。
b)随着创新业务的不断增加,业务的复杂及庞大的体量会产生错综复杂且规模巨大的结构化数据,这些都必然迫使企业对数据库的需求指向大规模、高可靠、高扩展及高性能。
(3)Hubble去中心化技术
Hubble去中心化技术,实现在一个分布众多节点的系统中,每个节点都可以高度自治。去中心化过程就是将数据拆分的过程,让每个节点成为自己的领导者,进而依据服务划分将数据从主体数据剥离出来。
示例:中心化就是在餐厅柜台点餐,柜台是中心,所有人都需要排队点餐;去中心化是餐厅在每个桌子上都有一个独立的二维码,顾客通过扫码即可点餐。
(4)Hubble硬核技术价值
a)支撑高并发业务:应用入口可无限水平扩展,高效支撑高并发事务交易。
b)减少运维成本:去中心化后所有的节点配置、硬件配置都是一样的,减少运维和硬件管理的复杂度;多个入口不会存在单点故障问题,减少了运维成本。
c)提高查询效率:每个节点都可以提供入口和查询服务,大大提升了资源利用率。