天云数据-Hubble 数据库团队第二期技术分享会于 2023 年 4 月 1 日在天云数据一楼大厅成功举办,第一期我们进入了分布式数据库的世界,对分布式数据库有了一定的了解,在第二期分享会中我们将从协议讲起,真正的迈进分布式数据库的大门。现将精心制作的讲解视频和内容分享出来,与大家共同学习,如果想了解更多的数据库技术,尽情期待第三期技术分享会。

真技术·万里行 No.2|谈谈协议,分布式数据库世界的“入口”
今天的演讲的主要内容是协议,第一期将Hubble的全貌概述出来了,本期我们将进入到每个技术的细节里面,同时大家也会对分享的内容产生更多的思考,一个是Hubble实现这些技术点的思考,一个是对技术点实现过程的思考。我们将会逐步的进行分享讲解这些技术点。
1. 当前国产数据库替换难点
当前国产数据库替换有很多难点,《2022年中国数据库行业年度分析报告》中提出在数据库替换过程中存在着应用修改量大、语法和功能兼容性弱、对被替换产品的内置函数、存储过程兼容性差等难点。

2. 数据库各协议之间的差异是什么?
今天我们分享的是协议,协议是数据库的入口,在访问数据库时一定是会有一个入口能够进入其中。数据库协议包含了MySQL协议、PG协议、Oracle协议、自定义协议等。MySQL协议是开源的,在国内使用的非常多。PG协议同样也是开源的协议,和MySQL协议并驾齐驱,但是PG协议的宽泛性比MySQL协议好很多。Oracle协议虽然本身是闭源的协议,但其在行业中沉淀积累了近四十年的历程,使用量非常大,是目前数据库行业的老大。其他协议包括DB2、SQLserver等,这些老牌的数据库都是沿用自己原创协议的路数。现在新兴的数据库的趋势是兼容MySQL协议或者PG协议。自定义协议是通过自定义的方式实现这样协议的一个模式。

我们把协议分成了上述的5个协议,接下来我们看下协议之间的差异。首先看到右侧的图,MySQL协议在发展的时候有很多分支,其中很重要的一个分支是MariaDB,MariaDB是直接从MySQL中分离出来的,有个函数是GTID函数,MySQL中它的函数由UUID作为唯一标识,MariaDB是0-1作为唯一标识,这样的话返回形式一个是15b57a66-e10d-11eb-a4de-7499a366173e:1-20000:1-20000;一个是id:0-1:20000。为什么要举这样一个例子呢,MySQL协议在做这样的分支的时候出现了一个问题,自身MariaDB是从完成MySQL源代码的基础下,他的协议和兼容性已经发生了很大的差异变化。所以MySQL在做的时候,它的各个分支都有自己独特的地方,各个协议之间的兼容性很难进行兼容。左图所示是MySQL协议的操作过程和PG协议中操作过程,MySQL协议中一个是客户端,一个是服务器。PG协议中一个是前端,一个是后端。

3. Hubble在协议选择的思考?
Hubble在协议的选择上是如何思考的?首先,如何实现独立,在协议上要保证完全独立可能会带来一个很大的问题,相当于我们要重新做一套体系。举个例子,我们新建一个大楼,其他大楼的模型都是一样的,但是我们重新建一个大楼和模型差异很大,就会在里面投入巨大的人力和精力。其次就在Oracle协议,MySQL协议,SQLserver协议等协议中,如何选择这些协议?如果仅支持一种协议会带来什么问题?以及国内外是如何选择协议的?
例如现在这个架构体系是一个NewSQL架构体系,在GoogleSpanner里面它是NewSQL架构的鼻祖。Google Spanner 选择了Mysql协议;Tidb、OceanBase兼容Mysql协议;OpenGauss 兼容PG协议,国内外在选择协议时有兼容MySQL协议的,也有兼容PG协议的。Hubble在选择协议时要考虑以上这些方向。

1)独立实现协议需要做哪些工作?
这些考虑的方向就是定位我们Hubble数据库应该如何更好的定义我们自己的协议。这个对于我们。如果说做独立协议实现的话,要做什么事情?首先要提供一个数据库的安装包和客户端驱动包;其次需要语言的支撑,目前已知的语言有270种,流行的编程语言有60多种,每种语言都要提供一个驱动包用于连接数据库;第三是需要多平台的支撑;第四是版本的维护。以上四点是独立实现协议的准备工作,需要投入大量精力的是开发平台和编程语言的驱动程序。

2)Hubble协议选择的初衷是什么?
Hubble协议选择的初衷是什么?选择一个已有的数据库协议做兼容,可以确保客户在使用Hubble数据库时不需要再学习新东西。

在众多协议中如何做抉择,我们将协议分为闭源协议和开源协议,闭源协议比较常用的是Oracle、Sql Server、DB2。如果使用这些协议,首先需要授权,其次是没有公开源代码,很难验证你的协议与Oracle协议是否完全兼容的。
开源协议客户生态系统已经相当成熟且已经在众多项目中广泛的使用,便于拓展数据库的客户群开源,开源可以自由检查其实现,以简化兼容性的实现。我们把开源协议做了一个圈定,如果我们把上面的条件都做为约束,那么可供选择的就缩小到了Mysql和Postgresql两个协议。

3)Hubble以PG协议为主要协议的原因
前面也提到了MySql协议本身它的割裂程度非常大,MySQL协议已经走向了一个各自的独立性和分裂性比较强的方向。PG的网络协议文档更清晰、更详细、更全面; PG的License更加的宽泛,SQL解析代码可以被重用;相比 Mysql 的License是禁止被重用的;MySQL文档和生态系统中仍然存在大量的缺陷。这是为什么选择PG协议为主要协议的四个原因。

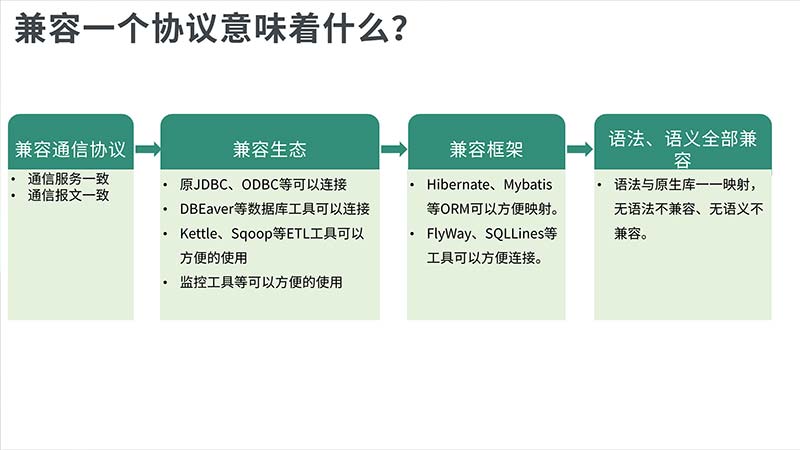
兼容一个协议意味着什么,Hubble已经确定以PG协议为主,那兼顾这样的协议意味着什么呢?首先要兼容这个协议,就要做到通信服务一致和通信报文一致,保证可以正常的通信连接。其次要兼容生态,兼容报文和兼容生态有什么区别?兼容报文相当于进入到了数据库大门里面,进入后要了解内部的东西,要进行交互等这就是需要兼容生态,生态兼容相当于围绕着数据库周边的一些工具,能够原封不动的进行使用。第一个兼容的是原生JDBC、ODBC,保证连接后不会报错;第二个兼容DBEaver等数据库工具可以连接,这样用一些工具可以访问数据库;第三个可以方便使用Kettle、Sqoop等ETL工具;第四个能够方便的使用监控工具。第三要兼容框架,兼容框架针对于代码人员可以更方便灵活的使用数据库。最后要做到兼容语法和语义,所有的SQL语句、体系能够完全与现有的数据库完成一模一样替换的模式。
协议是数据库的根本,它能够做到无缝衔接替换其他用户,通过协议的完全兼容实现了当前国产数据库替换的难点。
4. Hubble是否还会选择其他协议?
Hubble除了支持PG协议外也支持MySQL协议,为什么要支持MySQL协议,首先是市场需求,国内市场中大量使用了MySQL数据库,其次MySQL的开源体系中使用最多的。

协议兼容有几种实现机制,这也是我们要考虑的。首先第一种,直接修改源代码,原代码做分支起点较高,兼容性较好,但是受限于原有代码结构,变动困难且变动后无法再合并。例如MariaDB直接从MySQL数据库中做一个分支出来,然后进行修改,这是最简单的方式; 第二种是代理模式,代理模式把已有的数据库服务、报文兼容。在底层上实现SQL语句,通过底层数据库返回想要的结果。其他类型是中间加了一个代理层,这个代理层支撑的是我的服务,支撑着SQL语句的解析。把SQL语句落到数据库上,把数据库再返回模式。目前分布式中间件大部分走的是代理模式,代理模式作为中间件,中间件把SQL语句进行翻译。翻译完后,把SQL的模式直接分到各个底层的数据库上。
第三种是源码复用,例如,PG协议中有一个SWD ,SWD相当于外部数据的连接。很多基于PG协议复用会把PG协议本身作为源码,把SWD相当于外部数据表的连接作为一个外部源,再做一个分布式存储,PG协议作为上层的数据库的输入,外挂一个外部存储,通过这种形式实现源码复用,相当于复用了PostgreSQL自身的上层源码,通过外挂底层存储实现一个源码复用的方式;
第四种自主研发,从服务、报文、SQL协议、SQL解析、存储等全部自主研发,开发难度大,但是带来了巨大的可控和灵活性。

5. Hubble 在数据库协议下的实现细节
1)PG协议介绍
前面是我们对整个数据库协议的思考,接下来将进入到协议的具体介绍。PG协议分为启动和常规两个阶段,启动阶段首先是客户端尝试创建连接并发送授权信息,然后服务端反馈状态信息,连接成功创建。接下来进入常规阶段,客户端发送请求至服务端,服务端执行命令并将结果返回给客户端,客户端请求结束后可以主动发送报文断开连接。常规阶段中客户端通过两种“子协议”发送请求,一个是简单查询,简单查询就是直接把SQL语句直接发给客户端,服务端收到处理并返回结果,第二个是扩展查询,扩展查询中分为以下几个步骤:解析、绑定、定义、执行。

2)PG协议-报文格式
PG协议中的报文格式一个是启动报文,另一个是常规报文,这两个阶段的报文有什么区别?启动阶段没有报文类型字段,以报文长度开始,随后紧跟协议版本号,然后是键值对形式的连接信息,如用户名、数据库以及其他 GUC 参数和值。
常规报文有一个常规报文类型,报文的第一个字节标识报文类型,随后四个字节标识报文长度,具体的报文内容由报文类型决定。

3)PG协议-客户端报文标记
在客户端发送给服务端的报文中,报文对应着报文类型,是单个字符且区分大小写的一个报文类型。

4)PG协议-服务端报文标记
有客户端就会有服务端,客户端发送报文过去,服务端要有对应的响应,服务端报文也有对应的格式,包括常规报文中的解析完成、报错、绑定完成等。这些内容在客户端和服务端之间进行交互的时候做到连续性。

5)PG协议-创建连接
接下来我们看初始化报文,如何与客户端建立连接?PG协议中客户端是前端,服务端是后端,客户端发布一个启动报文,服务端需要判断是否需要授权信息,客户端会发送密码到服务端,服务端验证后会给客户端发一些参数信息,包括你的用户名、密码等等等。最后服务端发送准备好查询的报文给到客户端,就连接成功了。
建立完这个协议后可以直接互相访问连接,建立完连接后就进入了整体相互通信的常规阶段。

这是创建连接的一个简单代码的定义,左下角是开始的报文,里面包含了参数信息,右侧图为解析过程,相当于二进制的东西如何解析成报文模式。
6)PG协议-取消请求
提交任务后,如何取消请求?在启动阶段,服务端给客户端发送一个 BackendKeyData 报文,该报文中包含服务端的进程 ID 和取消码。如果客户端希望取消当前正在执行的请求,则可以发送一个取消请求的报文,该报文中包括启动阶段服务端提供的进程ID和取消码。
取消请求需创建一个新的连接,直接发送取消请求的报文,就可以取消请求。

7)PG协议-发送和处理请求
通常进入常规阶段之后呢,一个是客户端发送查询请求,服务端接受请求并处理后将结果返回客户端。该阶段有简单查询和扩展查询两个协议。

8)PG协议-简单查询
在简单查询中,只需将报文标记、报文长度和查询内容发送给服务端,服务端会返回两条信息:元数据信息描述和数据信息。客户端直接将SQL语句放在查询内容的位置,服务端很容易拿到SQL语句,之后将所有的元数据信息和数据信息返回,形成对应的报文体系。

这样的报文体系我们能够看到有以下几个阶段:首先是查询,查询后服务端返回结果发送完成,服务端发送一条命令完成报文。每个 SQL 命令执行完都会回复一条命令完成报文,查询请求执行结束会发送一条准备好查询的报文,告知客户端可以发送新的请求。

简单查询里面会返回一个事务状态,一个请求里面多条SQL语句会当成一个事务,如果事务是默认提交的话,一个事务失败后整个事务会回滚,为了避免整体事务回滚,可以在请求中显式添加定义,如:开始事务、结束事务等。将一个请求分为多个事务避免全部回滚。事务会反馈当前的几种状态:空闲状态、数的状态和数错误的状态,客户端可以根据事务状态做相应的处理。

9)PG协议-扩展查询
扩展查询处理流程分为若干步骤,每一步都有单独的报文。扩展查询使用的是服务端
预处理语句功能,相当于服务端收到SQL语句后对其进行解析、重写保存能够被复用,执行时直接使用预处理语句生成计划并执行,避免对同类型SQL重复解析,提升同类 SQL 多次执行的效率。扩展查询协议通常包括 5 个步骤,分别是从解析,捆绑,描述,执行和同步。

10)扩展查询-解析
扩展查询解析阶段相当于一个占位符的SQL语句,这样能够拿到报文体系中的报文长度、查询语句、参数个数和参数ID信息,会把报文体系发送到终端,终端通过对这样的报文做一个解析,解析完成后会返回一个执行计划。

11)扩展查询-绑定
解析完后第二步做绑定,客户端发送绑定报文,报文中包含具体的参数值、参数格式和返回列的格式。当服务端收到绑定报文后,调用bind函数进行处理,之前保存的预处理语句创建执行计划并保存在缓存计划中,并创建一个网关用于后续执行。
定义portal相当于在数据库里面做了一个预处理语句,然后会把这个体系定义为一个portal。可以同时访问portal且可以复用portal,这样可以减少计划的重新解析,因为一个SQL语句会解析为一个逻辑计划,计划是连续保存下来后续使用的,后续使用时性能会有很大提升。在PG协议中。本身支持多个portal共同使用,在这个数据没拿完之前就可以启动了,这是portal的定义。

12)扩展查询-描述
第三步是描述,客户端可以发送描述报文获取 statment或 Portal的元信息,然后返回结果的列名,类型等信息,这些信息体现在 RowDescription 报文上。如果请求获取 Statement 的元信息,还会返回具体的参数信息,在 ParameterDescription 报文上体现。因为SQL语句本身已经实现了内部解析,如果要复用一个SQL语句,通过获取参数信息就可以复用整个协议的过程。

13)扩展查询-执行
第四步是执行,客户端将执行报文发送给服务端,服务端收到报文后,执行绑定阶段创建的Portal,执行结果通过DataRow报文返回给客户端,执行完成后发送完成命令。执行报文中可以指定返回的行数,若行数是 0,表示返回所有行。

14)扩展查询-同步
当扩展查询执行完后客户端会收到一个Sync报文,然后服务端回到等待查询的状态,右侧图中是客户端给服务端发送信息后服务端给客户端回复消息的流程,通过解析、绑定、描述、执行和同步五个步骤整体串联形成一个SQL语句执行全过程。

除了简单查询和扩展查询两个过程外,还有一个协议是copy子协议,这个协议是为了提高整个数据导入导出的速度,通过copy from这个命令,可以提升导入和导出数据的速度。

Copy子协议的一个流程是从查询-复制访问开始,通过响应后开始不断的复制数据,复制完成后,返回已完成命令,已准备好查询。
协议是整体的入口,有这样的协议,才能够保证在使用数据库或迁移数据库的时候,能够平滑的做迁移。在协议里面的话会看到很多重复的地方,原因是确保你的协议能够给其他协议进行兼容,入口建立完成后。

